Initial Claude Opus 4.7 Impressions: Massive tokens eater
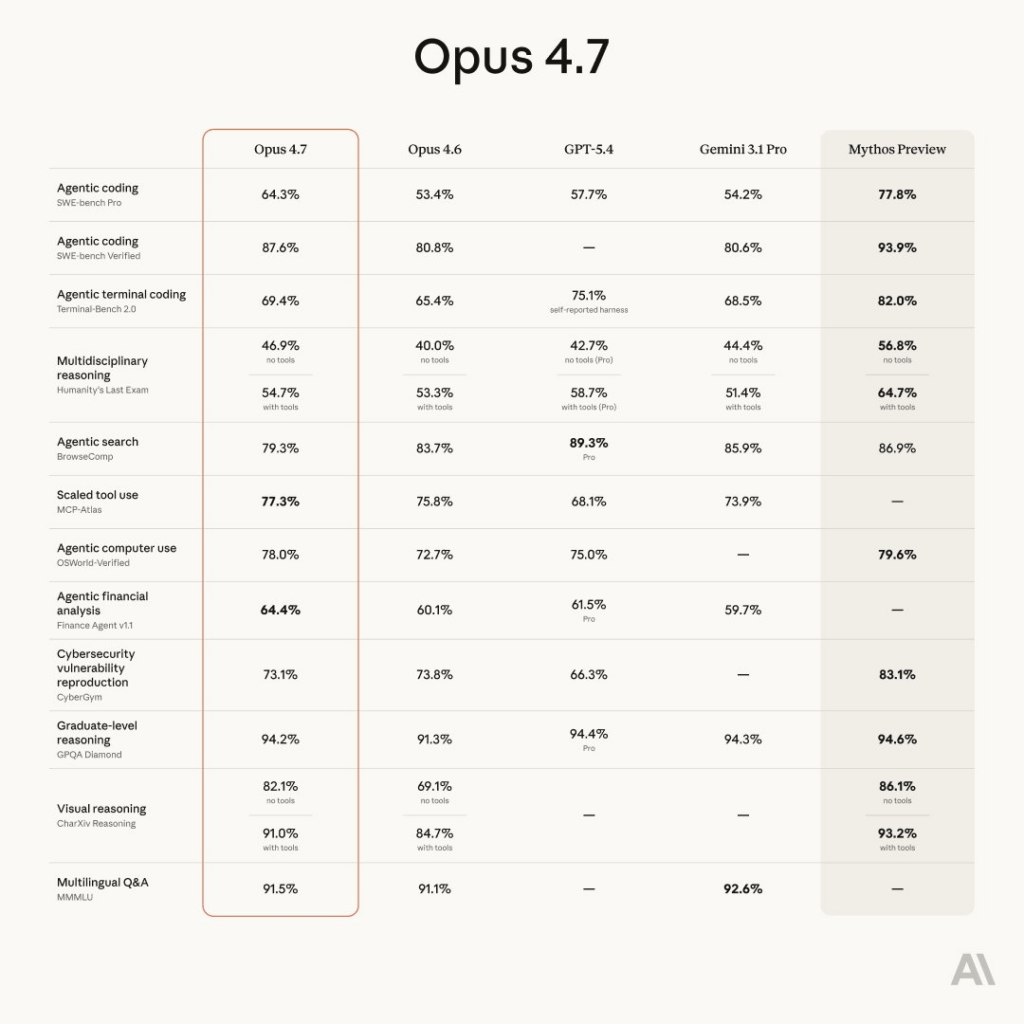
Anthropic’s Claude released its frontier model Opus 4.7 last night. According to Anthropic, It takes on long-running tasks with impressive dedication, following instructions with meticulous attention and double-checking its results before sharing them. The earlier version of Opus was 4.6. It carries the same pricing as 4.6 ($5/$25 per million tokens) and is available across API, Bedrock, Vertex AI, and Microsoft Foundry.
Table of Contents
Are Claude Opus 4.7 Impressions negative?
While we cannot term the impressions negative, people report not seeing a large-scale difference between 4.6 and 4.7, with a few reports on Twitter that the model is performing at an average level compared to its predecessor. (Claude being lazy is a problem anyway for all their models, these days.
Another aspect people have been talking about is that this feels more like Sonnet 4.6 where there are multiple reports of:
- No improvement in Coding quality.
- Drop in Long Context reasoning.
- No manual override of the thinking effort in the Interface.
- Preferences specified and Web search citations are ignored.
- Excessive malware reports with Custom files.
Updated Tokenizer
In the Blog Post, Anthropic mentions that Opus 4.7 uses an updated tokenizer that improves the model’s text processing. The tradeoff is that the same input can map to more tokens, roughly 1.0-1.35x depending on the content type. Essentially, earlier, if on the Pro plan, you got timed out quickly, expect to be even more so if you plan to use 4.7. We covered it here.
However, Anthropic has said that since Opus uses more thinking tokens, the rate limits have been eased for the time being.
Positive Impressions
The Claude Opus 4.7 impressions are also positive, as per many users, although the negative comments far outnumber. Here are some positive impressions:
- It excels at handling complex, long-running tasks such as deep research, code refactoring, building intricate features, and iterating until it meets a performance benchmark.
- Follows instructions/CLAUDE .md much better than Opus 4.6
- checks its own work before responding. less broken code. less confident, wrong answers.
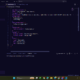
- Insane quality of CAD work.
- Better at reading Binaries like Photos and Documents.
Opus 4.7 appears to be SOTA at agentic CAD design pic.twitter.com/m1DeQRC13u
— adam (@adamdotnew) April 16, 2026
At the end the Claude Opus 4.7 Impressions appears to be pretty mixed. Are you happy with the results if you have tried? Let us know in the comments.